Hidden Markov Model and Part-of-Speech Tagging

We know that to model any problem using a Hidden Markov Model we need a set of observations and a set of possible states. The states in an HMM are hidden.
In the part of speech tagging problem, the observations are the words themselves in the given sequence.
As for the states, which are hidden, these would be the POS tags for the words.
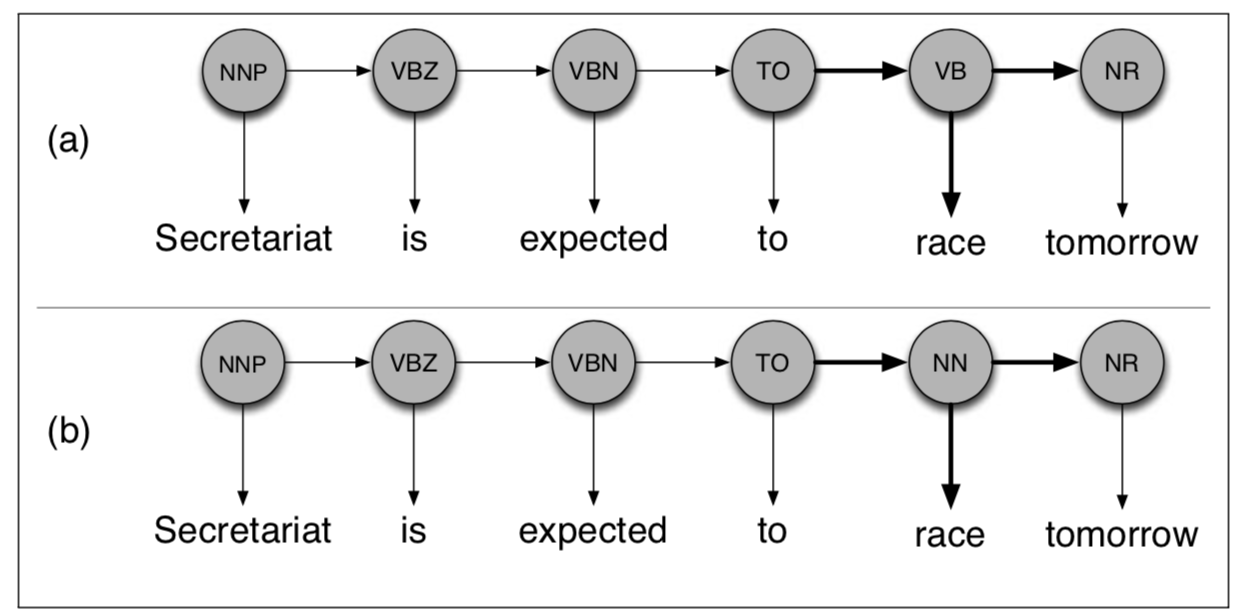
The transition probabilities would be like P(VP | NP) which means the probability of the current word having a tag of Verb Phrase given that the previous tag was a Noun Phrase.
Emission probabilities would be P(Joe | NP), which means the probability that the word is, say, Joe given that the tag is a Noun Phrase.